Searching Publications for Proliferation Activities
One of the projects that I've been supporting this year is applying natural language processing techniques to a technical publication dataset to help identify activities that might be related to nuclear proliferation work. As the "data czar" for this project, I investigated multiple sources (e.g., Scopus, Semantic Scholar, OSTI) where we could get a baseline corpus of technical papers we could inspect. In the end, OSTI.gov was the least difficult to obtain and had a lot of interesting info in it. I pulled a large chunk of it, organized it, and did the first pass data engineering to get it into a usable form (turns out there are literally hundreds of ways Sandians identify their laboratories). Jon, Danny, and Zoe did a good bit of analysis on this data, which resulted in this paper at the Institute of Nuclear Materials Management (INMM) annual meeting.
Abstract
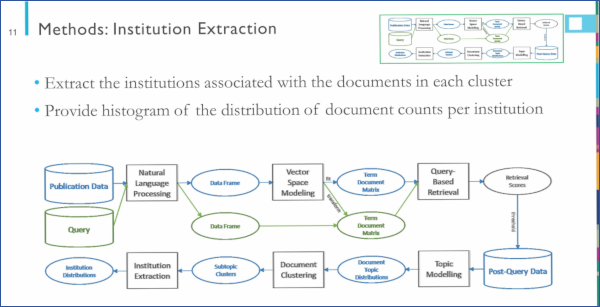
Scientific and technical publications can provide relevant information regarding the technical capabilities of a state, the location of nuclear materials and related research activities within that state, and international partnerships and collaborations. Nuclear proliferation analysts monitor scientific and technical publications using complex word searches defined by fuel cycle experts as part of their collection and analysis of all potentially relevant information. These search strings have been refined over time by fuel cycle experts and other analysts but represent a top-down approach that is inherently defined by the requirement of term presence. In contrast, we are developing a bottom-up approach in which we develop topic models from a small number of expert refereed source documents to search similar topic space, with the hope that we can use this method to identify publications that are relevant to the proliferation detection problems space without necessarily conforming to the expert-derived rule base. We are comparing our results of various topic modeling and clustering techniques to a traditional analyst search strings to determine how well our methods work to find seed documents. We also present how our methods provide added benefit over traditional search by organizing the retrieved documents into topic-oriented clusters. Finally, we present distributions of author institutions to facilitate a broader perspective of the content of interest for analysts.
Publications
- INMM Paper Jonathan Bisila, Daniel M. Dunlavy, Zoe N. Gastelum, and Craig D. Ulmer, "Topic Modeling with Natural Language Processing for Identification of Nuclear Proliferation-Relevant Scientific and Technical Publications", in Proceedings of the Institute of Nuclear Materials Management (INMM) 61st Annual Meeting, July 12, 2020.
Presentations
- INMM Slides Presentation that Jon gave virtually at INMM.