Viz-NIC for FPGAs
After completing the FPGA-based network intrusion detection system (NIDS) project, I became interested in building other FPGA designs that could leverage the networking features of the Virtex II/Pro (V2P) architecture. While layer two packet processing was fairly straightforward, it was clear the real win would be if I could build a more advanced network interface (NI) for the FPGA that could speak to a remote computer using a TCP socket. Building such a NI is useful for distributed systems work because it enables you to do computations in the FPGA and then transmit the results to another host somewhere in the network. After a great deal of effort I built something I think is fairly novel: an FPGA hardware core for transmitting OpenGL graphics primitives over TCP. This "Viz NIC" allowed us to build an isosurfacing engine in hardware and then transmit Chromium-encoded polygons to a remote node for rendering.

Network Interface
As I mentioned in the NIDS post, the Xilinx V2P features a number of specialized hardware components that greatly simplify the amount of work you have to do to use FPGAs in network applications. The NIDS project taught me that a RocketIO module can handle physical layer operations and that simple state machines can be written in hardware to do layer 2 packet processing. I'd also learned in other projects that the PowerPC cores provide a convenient place to implement higher-level protocols in software (though unfortunately I was too hardware macho when I started this project to admit that some things should be done in software).
I started with a simple layout for building my NI that split the working into three units: a Gigabit Ethernet (GigE) unit for dealing with packets, a TCP Offload Engine (TOE) for handling byte streams, and a Chromium unit for packing OpenGL primitives into the byte stream. While the design was greatly simplified by the fact that our NI only needed to maintain one connection, I still had to implement all the subtle behaviors of TCP and Ethernet to get the NI to speak to anything. After I was a good bit into the implementation, I realized there were a number of subtle behaviors in TCP software stacks that you have to emulate in order to keep the destination happy. In retrospect, it would have been a lot easier to implement the protocol in software. The below diagram shows the architecture for the lower two layers of the Viz NIC.

GigE Layer
The first step to building the NI was constructing a GigE layer that handled simple packet processing. While I was able to reuse some of the GigE NI hardware I built for the NIDS, I had to build additional units for dealing with both ARP and Ping packets. ARP is used to translate between IP and MAC addresses, and uses simple broadcast requests/replies to share information among nodes. I built a 256-entry IP-to-MAC cache to translate addresses on my (limited) subnet, and updated the cache whenever new ARPs arrived. For outgoing IP packets, the GigE layer filled in the MAC address when it became available. If a translation wasn't available, the unit would automatically broadcast ARP requests until the address was discovered. To help with debugging, I added a Ping reply handler to the GigE unit. This handler caught ICMP echo requests and transmitted the proper replies. Given that there are many places where things can go wrong in a network, ping handling was a great way to verify the NI was still at least partially functional.
TCP Offload Engine (TOE)
The next layer in the NI was a TCP Offload Engine (TOE), which implemented the bulk of the TCP protocol. TCP's job is to provide users with a simple byte stream interface that runs on top of a lossy, packetized network. The user interface into the TOE is thus a simple FIFO-like API. The TOE maintains data structures to allow packets arriving from the network to fill an incoming queue, and organizes data from the outgoing interface to MTU-sized packets. Outgoing packets have their TCP CRCs generated as data is streamed into the TOE (annoyingly, the CRC needs to be placed in the TCP header in the front of the packet instead of the tail). Outgoing packets have to be held in the queue until the receiver acknowledges they've been received.
The hard part about implementing the TOE was encoding all of TCP's behaviors. Connections are setup and torn down through a series of control messages. The TOE maintains packet sequence numbers and uses information from incoming messages to determine whether data has been transferred correctly and make decisions about when buffers can be released. In order to deal with IP's lossy nature, the system employs a timeout monitor for outgoing packets. For simplicity, the system uses a "go-back-n" approach to retransmitting bad packets instead of "selective repeat". Additionally, the outgoing state machine doesn't try too hard to pack multiple small data bundles together (Nagle's algorithm)- a packet is launched when the user says to, or the MTU is reached.
Chromium OpenGL Transport
Being that I worked in a Viz group, I was primarily interested in using the FPGA as a device for performing visualization operations. OpenGL is a well-known standard for rendering graphics and provides a number of primitives for referencing graphics data structures (vertices, lines, polygons, etc). Scientific users often turn to distributed computing for visualization due to the size of their datasets, and need a way to ship OpenGL primitives around in the network. Libraries such as WireGL and Chromium provide a serialization layer to efficiently pack OpenGL primitives into packets. We decided to use Chromium's data format for our Viz NIC instead of designing our own because it enabled us to plug into their framework and use their rendering code. The Chromium layer was much easier to implement than TCP because its operating environment is much simpler: the user opens a new connection, starts a new frame, sends a long series of triangles, and then marks the end of the frame. I looked at a few different ways to pack the triangles efficiently (e.g., triangle strips), but in the end I just pushed them out individually, knowing that multiple triangles would get bundled together into each packet. This strategy made it easy for the user to present a new triangle input every clock.

Isosurfacing Engine
I needed something to supply data to the Viz NIC, so I built an isosurfacing engine that thresholded a 3D volume of data and produced a triangle shell representing the threshold contour. Isosurfacing is a common technique used in viz, and is a good example for accelerator work because it involves a fair amount of computation on independent data. I built an implementation that was based on Marching Cubes. In MC, you pull an individual cube of eight data values, threshold them, and then pick one of 256 triangle representations that best match the threshold outcomes to represent the contours that pass through the cube. The computation involves eight trivial thresholds, a lookup, generating 8 midpoint vertices along the edges, and constructing the corresponding triangles (using the updated vertices). The trick is streaming the input data into the unit in a way that maximizes the rate you can fetch data, since there is a large amount of data reuse in the algorithm and the input data can be big. I tried a few different approaches on different platforms. On a standalone V2P dev card I used a tiny 16KB on-chip buffer that a PowerPC could fill with data. On the Cray XD1 I used their external QDR memory and exploited its wide data path to pull many cubes out at once. I found some medical datasets to use for input data and then resampled them to a few resolutions (64x64x64 and 128x128x128). Below are two renderings from my implementation. I rendered without any shading so you could see how Marching Cubes chunks things up into level sets.
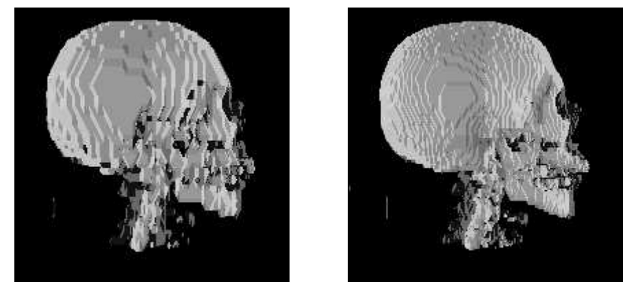
Rise and Fall of Viz-NIC
The Viz-NIC was a fun and challenging project that took a great deal of time to complete. I liked this project because it touched on many different things that I was working on at the time: FPGA hardware design, custom network interfaces, graphics libraries, and visualization algorithms. I was fortunate to have a viz coworker guide me through the viz side of things and explain how scientific users looked through their datasets. Digging into the network stack was a good experience as well. I learned a great deal about the internals of network stacks in this project, from bits-on-the-wire Ethernet framing to debugging TCP sequence numbers with Wireshark.
Unfortunately, I didn't get a real publication out of all this work. I wrote up a paper on the work (below) and submitted it to an FPGA conference, but it got rejected for not having a good accelerator story behind it. As I looked around for other conferences where I could submit it, I realized that it'd be difficult to publish it anywhere because it didn't have a strong story for any individual discipline. It had an FPGA aspect but lacked an acceleration story. It had a networking aspect but wasn't research because it was Ethernet. It had a viz aspect but wasn't doing anything new in terms of viz algorithms. While the value of the work may be that it combined multiple disciplines to do something (that I thought was) new, it didn't do it in a way that would impact any of the disciplines, and therefore wasn't something that could be published. In any case I still think it's one of the most interesting and hard core things I did during my FPGA years.
Publications
Even though I didn't find a place to publish the paper, I did get it reviewed and approved for external release. Here's a copy of where I was at with it in 2005.
VizNic Draft Craig Ulmer and David Thompson, "A Network Interface for Enabling Visualization with FPGAs", draft