Close, but no blimp data. Last Thursday at my son's soccer practice, one of the Goodyear Blimps circled the field as it descended for a landing at the Livermore Airport. It was a little surreal, since it looked like the blimp was monitoring the practice the same way it circles big bowl games. However, blimp sightings aren't that uncommon out here. Livermore is on the fringe of the Bay Area and we have a large municipal airport with wide open spaces around it. It seems like the perfect place to launch, land, and park a blimp if you knew you were going to be visiting the area by dirigible airship.

Sunday morning I started wondering where the blimp was going while it was in the area. Since I've been running a dump1090 data logger on my Edison board for the last few weeks, I began pulling the data and parsing it for signs of dirigibles. As I was puzzling through how I might identify a blimp in the pile of points, I heard a faint buzzing sound coming from outside and realized that the blimp was at that very moment passing by my house.
Getting the ID From Dump1090
I went over to the webpage that dump1090 generates to see what aircraft were in the local area. I was disappointed to see that the map was pretty much empty nearby, which meant that the blimp wasn't transmitting position data. I looked at the list of planes and noticed that there were some planes in the area that were reporting their presence, but not identifying their position. I sorted them by altitude and found one that was cruising along at only 2,000ft with an ICAO hex ID of A4A7EF. Some searching around and I found this ID belongs to tail N4A, which is a 33-year-old (!) blimp owned by Goodyear.
Looking it up in FR24
While I was disappointed that my own logger didn't get any position info for the blimp, I knew that other aviation sites have tracks for aircraft based on other data sources. I looked it up on FlightRadar24 and found that they had logged a few flights for the blimp on Saturday:
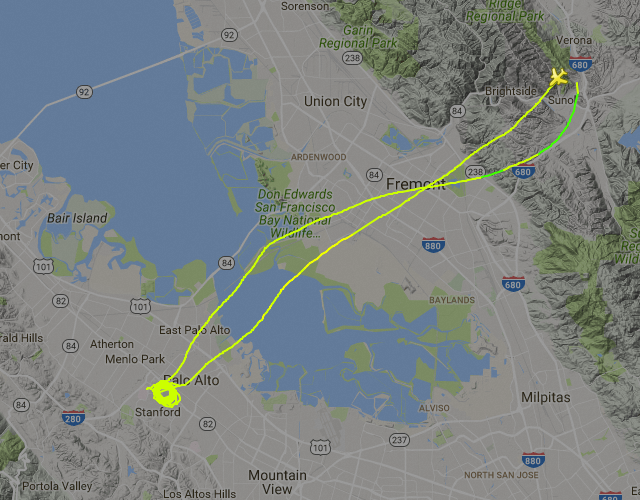
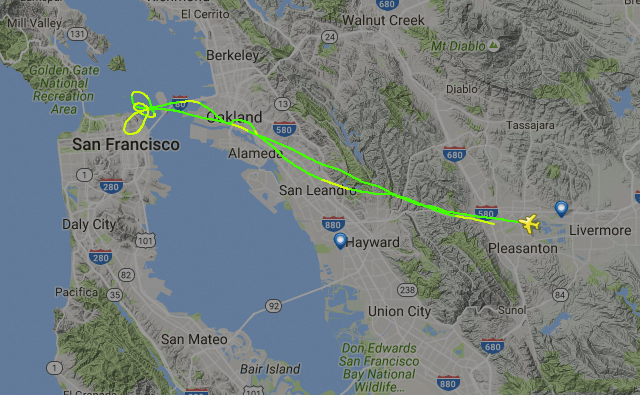
Well, that solves the mystery: they were out here to watch Stanford play against USC (for the people back home, that's U of Southern California, not South Carolina). They circled that stadium for more than 5 hours, trying to make sense out of the whole situation. Then they went and blew some steam off in San Francisco. I'd like to think that the highlight of their trip though was watching my son's soccer team practice.
2016-06-02 Thu
data text code
Craigslist is an interesting source of text data. In addition to providing a continuous stream of user postings from around the country in organized categories, the website stubbornly favors a plain-old-web format that's easy to retrieve and parse. I believe craigslist gets a lot of traffic from different kinds of scrapers. In addition to all the search engine crawlers, you hear stories about how individuals run scripts to continuously watch their local boards so they can be the first to snatch up free items. Craigslist blocks people that aggressively crawl the site, but otherwise let you wander around if you put in some rational delays.
Back in September I wrote some utilities to go off and scrape job postings from craigslist, because I thought it would be interesting to see what kind of people Bay Area companies wanted. After working out how to grab the data in an unobtrusive way, I updated my script to grab tech job postings from different cities around the country. I run the script about once a week, which over the last 9 months has given me about 32k postings, totaling 470MB in text data. This post just focuses on the scraping. I'll get to the analysis later.
Scraping
Craigslist puts each post as a separate web page, and uses a city/topic/post directory structure to keep things organized. While the post part of the url is unique and non-sequential, they provide an easy-to-parse index page for each topic that will give you all the urls for the posts in reverse chronological order. All one has to do is pick a city and a topic, walk through the index, and retrieve the individual posts. I put some delay in after every page I fetched to be polite. I also randomized the city list on each run to even out the data if the grabs were taking too long and needed to be cut off (though always getting ATL would have been fine for me). To help with statistics, I had the script store basic information about runs in a local sqlite database. The database helps avoid downloading the same post twice, and gives me a place to store the dates of when I first and last saw a particular post.
Grabs Per Day
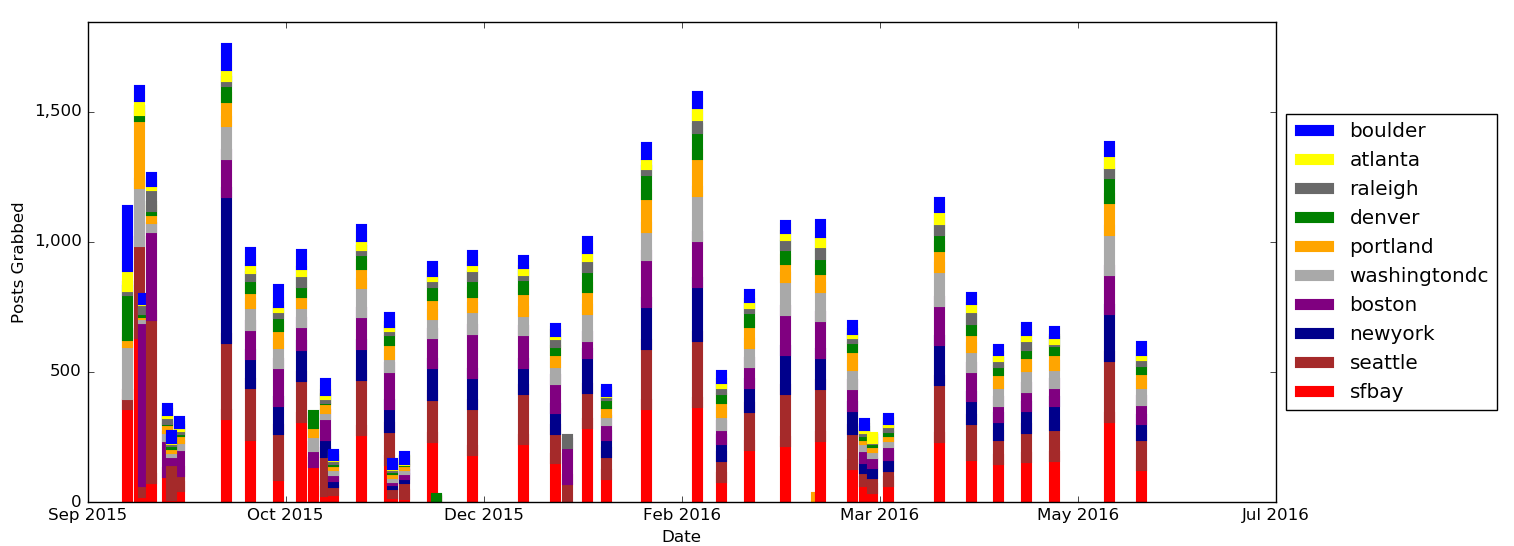
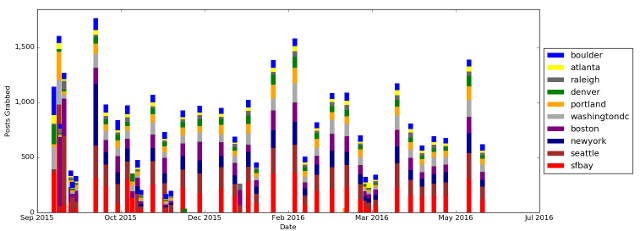
Below is a breakdown of how many posts I grabbed for each city when I ran the scraper. Since the script only grabs posts that it hasn't seen before, the per day grabs go up and down based on how frequently I ran the script (eg, when I missed a week or two, there was more data available to grab). For this time period, the cities seem to be fairly proportional. The big job cities seem to be San Francisco, Seattle, New York, and Boston (not unexpected). C'mon Atlanta. It's like you're not even trying.
Number of Active Days per Post
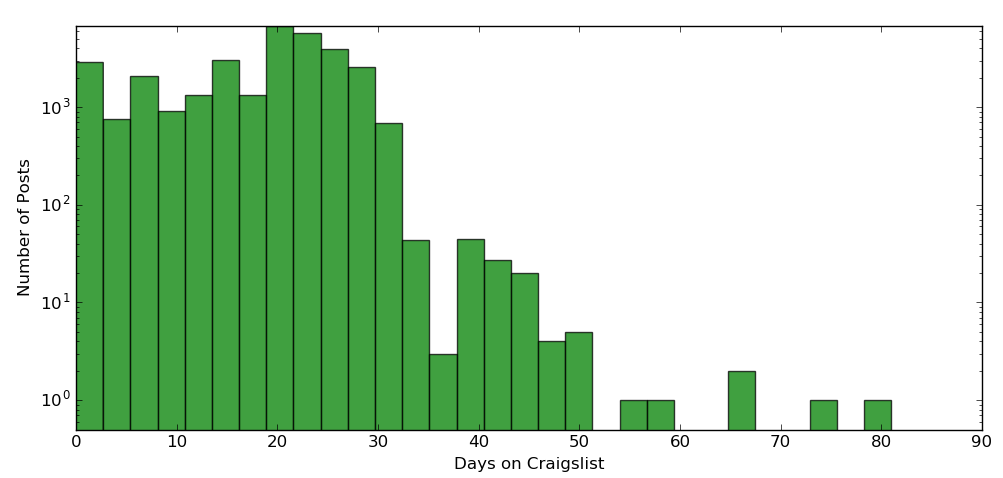
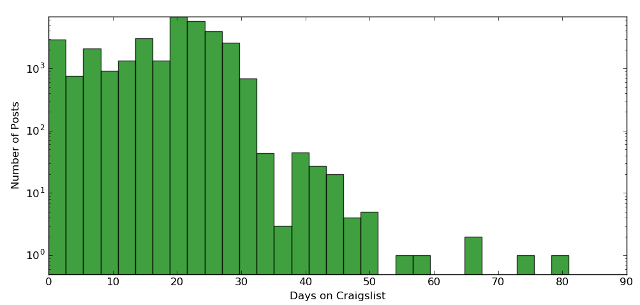
Another interesting statistic for me was how long job postings remain active on craigslist. I used the "first seen" and "last seen" dates stored in my meta data to estimate the amount of time I post stays alive. The numbers are off due to the initial posts I pulled (ie, I looked at the grab date instead of the post date) and the most recent posts (ie, which have not expired yet). As the below (logscale!) plot shows, most posts stick around for about a month. However, there are a few the last as long as 80 days.
Code
It isn't much but I put the code for this on github:
2016-04-29 Fri
planes code
In addition to being an interesting source of data for plane statistics, the FAA registration dataset also provides address information for each plane's owner. I was curious to see who owned airplanes in my town (not just the drones), so I wrote a simple script to extract addresses in my zipcode from the database and convert them to geospatial coordinates. Below is a plot of all the registered plane owners for Livermore. I've also outlined different neighborhoods in town and colored them by how expensive their houses are. Unsurprisingly, people that own planes tend to live in wealthier neighborhoods.
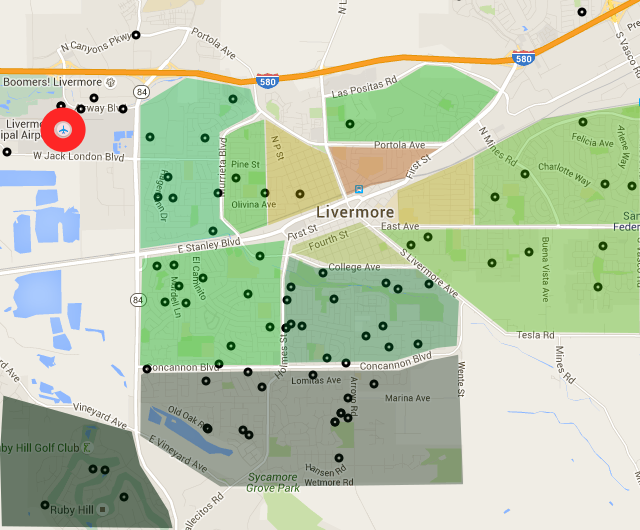
Livermore
Livermore has a busy municipal airport on the north-west side of town, with an east-west landing strip. Planes typically approach the airport by flying west over the city, using the railroad and I580 as visual guides to locate the airport. People that live east of the airport often complain about the noise of descending planes, but the airport was there long before the houses (it was built in 1965). In general, Livermore house prices increase the farther south you get. The cheap houses (where I live, in the yellow) start at about $500k. Down in Ruby Hill they're all well over $1M.
For the above plot, I shaded different parts of town based on how expensive their houses are: the darker green the color, the more wealthy the neighborhood. The shading wasn't very scientific- I just boxed up regions by hand and then looked up what Zillow said houses were going for in the neighborhood. Sadly, I found that my yellow-ish neighborhood had zero plane owners, which was consistent with other poorer neighborhoods. I think it's interesting that most of the plane owners live south of the landing path. I'm not sure if that's because that's where the more expensive houses usually are, or if plane owners are smart enough to know not to live long the flight path.
East Bay Owners
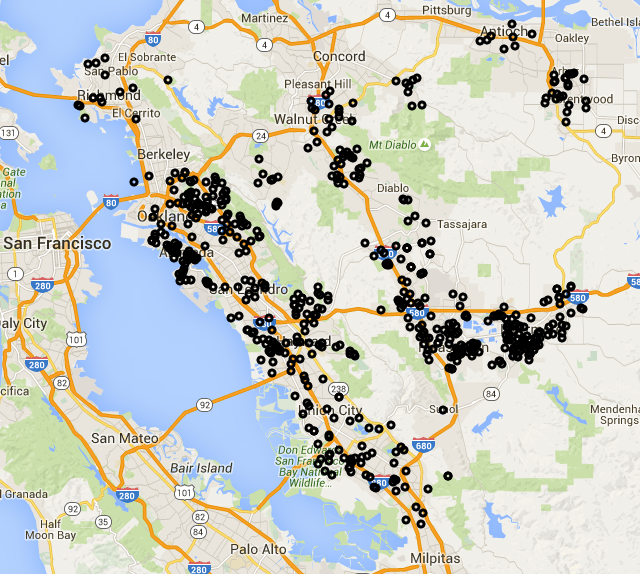
In addition to Livermore, I pulled out data on the neighboring areas (basically all of Alameda and Contra Costa counties). Below is a snapshot of it, but you can explore the data yourself in pannable Google map of the data.
Code
The fun part of this project for me was learning how to do two new things. First, I had to figure out how to translate street addresses into geospatial coordinates. I found that the GeoPy library does all the hard work for you by submitting your queries to different web services that do this kind of translation. I initially queried to frequently and got my IP address temporarily blocked, so I added a three second delay between queries to be polite. The translations aren't perfect (the FAA data is fairly dirty), but they were good enough to handle the majority of my requests. Second, I needed a better way to plot points. Previously I've used Mapnik and Pylab to render maps, but they're tedious to script up properly. I hadn't tried Google's Maps API before, but I guessed it'd be easy since so many people use it. I signed up for my first API key, modified a Javascript example they provided, and it magically did everything I needed. I feel kind of silly for not messing with it sooner.
The script I used for extracting the data is extract_by_zipcode.py, which I've put in my flight classifier repo. GeoPy needs a newer version of Python than what my CentOS 6 desktop had, so I had to build/install that as well.
github:flight-classifier
2016-04-10 Sun
planes code
While looking planes up in the FAA dataset for the previous post, I noticed some planes had zero seats, weighed under 55 pounds, and were electric powered. Drones! (or more officially, sUAS - Small Unmanned Aircraft System). I knew that the FAA was making people register their drones, but I was surprised to see them showing up with other aircraft in the FAA database. After a little reading I learned that there are actually two ways to register: (1) online through a simple, instantaneous web page or (2) by mail using the traditional paper form process. While the by-mail approach takes a few weeks, your drone gets an N number and is plugged into the database. I wrote some python scripts to pull out electric plane registration info and plot it.
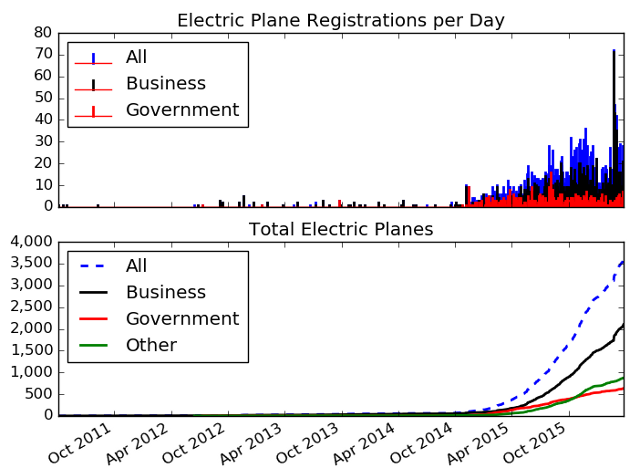
3,500 drone registrations is tiny compared to the web registration numbers (more than 300k in the first month). Still, it seems like a lot to me, given that I don't see an obvious reason to go through the by-mail process. In any case, I started filtering the data to see which organizations were registering. It wasn't that difficult, since the FAA database provides a registration type that identifies whether the owner is an individual, a corporation, or a government entity.
Commercial Drones
I first filtered on commercial entities, of which there were 940 different companies. Below is the complete list of companies with 10 or more drones. There are a few interesting stories here. First, Intel topped the charts with 111 drones. They seemed to all be the same ArsTec Hummingbird model, which (surprise) uses an Intel Atom Z530. BNSF Railway is using the drones to inspect rail lines (why not just strap a camera to a train?). Liberty Mutual says they're using them to assess insurance claims (eg natural disasters). San Diego Gas and Electric will do inspections of their service areas. Some companies do general "aerolytics", like this Talon Aerolytics video shows. Lockheed Martin manufactures their own drones. In addition to the electric models, their Missles and Fire Control group has a few drones under 55 pounds that use turbo-ject engines. There are also some mysteries in this list. Ashfloyd LLC has little outward info for a company with so many drones, causing some people to wonder who they are.
DRONES COMPANY
------ -------------------------------
111 Intel Corp
93 Precisionhawk Usa Inc
43 Ashfloyd LLC
40 Aerovironment Inc
23 Rotor F/X LLC
22 Lockheed Martin Corp
18 San Diego Gas & Electric
17 Unmanned Innovation Inc Dba
16 Talon Aerolytics LLC
15 Wintec Arrowmaker
14 Flirtey Inc
13 Trimble Navigation Ltd
12 BNSF Railway UAS Program
12 Precision Hawk Usa Inc
12 Cape Productions Inc
12 Microsoft Corp
12 Aerodrome LLC
11 Hazon Solutions LLC
11 Liberty Mutual Insurance
11 Unconventional Concepts Inc
10 Aerocine Ventures Inc
10 Amazon Logistics Inc
I was a little surprised Amazon didn't have more given Amazon Prime Air. They currently have 10 drones with tail fins, and have registered four different models they've developed. They've been adding to their inventory since last year, and appear to have more in the works if you check with the FAA. Here are the counts for the different models:
Model Number Tailfins Currently Registered
------------------------------------------------
MK9A 0
MK021A 2 Starting March 2015
MK23A 1 December 2015
MK24 7 Starting April 2015
Government Drones
Next, I selected on Government users, which yielded 310 organizations. They're not as exciting as people would things though- they're mostly state schools, NASA, fire departments, and law enforcement.
DRONES ORGANIZATION
------ -------------------------------
32 Kansas State University
22 Oregon State University
21 Nasa Langley Research Center
16 University Of Colorado
14 Nasa Ames Research Center
12 Virginia Polytechnic Institute & State University
12 Department Of Commerce
11 University Of Maryland Uas Test Site
11 Georgia Institute Of Technology
11 Cochise Community College
10 University Of Alaska Fairbanks
10 University Of Michigan
9 University Of North Dakota
8 Department Of Energy
8 Center For Disaster Risk Policy
7 Mississippi State University
7 Sinclair Community College
7 Auburn University
6 Ohio State University
6 Utah State University
...
4 Bureau Of Alcohol Tobacco Firearms & Explosives
3 Alameda County Sheriffs Office
Locust
MIT Lincoln Laboratory also popped up in the Aircraft Reference file (which defines airplane types), but does not show up as an owner of a registered plane in the master list. Searching for the drone's manufacturer model number in the master list turned up 9 hits, though all of them had their blank fields for the owner. There are many blanked owner fields in the dataset, so this may just be part of the registration process and not obfuscation.
The drone's name is Locust, which appears to be a micro-UAV developed by students in MIT's Beaverworks program, commissioned by LL and the USAF back in 2010. Some former students mentioned working on LOCUSTS/PERDIX in their LinkedIn pages, and that they'd designed micro-uavs that could be deployed at 30,000ft from a "cartridge mounted on a business jet". I don't know if it's releated or not, but the Office of Naval Research has a video of their LOCUST (low-cost uav swarm technology). Didn't these people watch Terminator?
Code
The above plots and data were generated with plot_drones.py and tally_drones.py, which I've put in my flight-classifier repo.
github:flight-classifier
2016-03-13 Sun
planes code
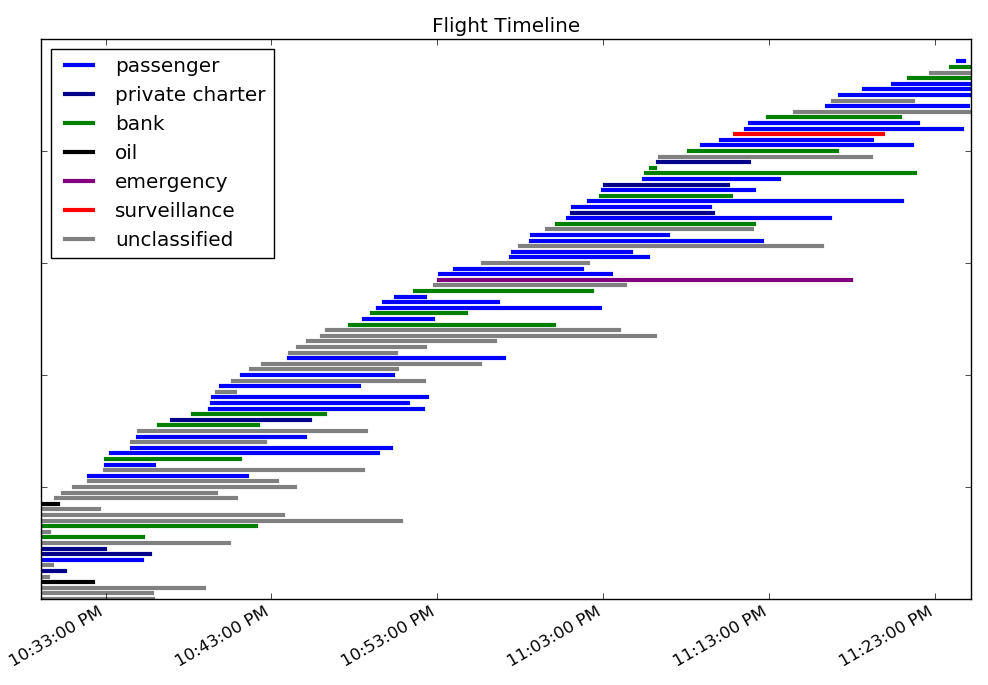
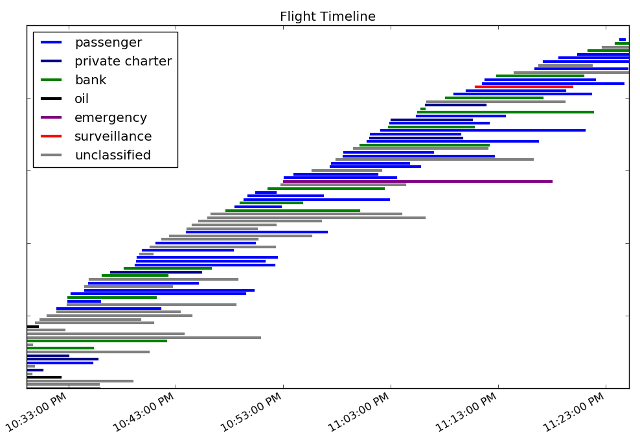
Earlier this year the local Livermore paper had some articles about how air traffic at our municipal airport was going to shoot up during the Superbowl, because there weren't going to be enough places for private jets to land in the Bay Area. I didn't think much of it at the time, since the paper tends to have delusions about how rich people will fly to Livermore and spend time here. However, after the Superbowl, my wife noticed on social media that several of her local friends were chatting about how there were a lot of jets taking off from the airport that night. I fired up dump1090 and let it grab for an hour before bed. After a bit of post-processing work, here's a timeline for all the flights I saw:
Post Processing
Dump1090 is a great program- in addition to displaying where planes are in a webpage, it produces easy-to-parse dump files that contain a good bit of plane information. I captured two types of traces from dump1090 after the Superbowl: the detailed runtime output with all the message info and the distilled, csv-formatted data from the netcat interface. The grabs went on for about an hour and yielded 30MB and 13MB of data, respectively. Looking at the data, I saw basically what I expected: there were a large number of private planes, but none of them were reporting position information. It drives me crazy that they clearly have ADS-B equipment but don't transmit position. Current regulations don't require it though, so nearly all private planes turn it off to prevent you from tracking their exact locations.
The dataset did leave me with a big pile of timestamped ADS-B IDs though, so I started looking for ways I could convert the IDs to something more interesting. I found that the FAA provides an extremely useful database you can download that contains full registration information for all US planes. The database is a collection of easily-parsed CSV files, and contains each plane's ADS-B hex code, tailfin, plane type, and owner information. The master DB files are currently close to 200MB uncompressed, but when I extracted just the ADS-B id and owner columns, it was only about 8MB (small enough for a quick lookup table use).
I used the FAA info to find the owners of the planes in my dataset, and then did some simple text processing to assign a classification to each plane to group similar owners together. Since I only had 98 planes to look at, I mostly did the classifications by hand. 36 of the planes were easy to classify because they were owned by commercial, passenger airline companies like Delta. Another 16 planes were owned by banks (fun fact: banks own more planes than any other type of company). Through some Google searches, I identified four private passenger carriers (e.g., Xojet) that took care of 7 more planes. I found 2 more planes owned by oil companies (Eaton and San Joaquin Refining) and 1 emergency helicopter (California Shock Trauma). I also found a plane owned by a gun store and another by a trucking company. There were 21 other planes in the FAA dataset that didn't turn much up in Google searches, that I marked as unclassified. That left me with 15 planes that weren't in the FAA dataset.
Foreign Planes
The FAA dataset only has info on US planes, so I figured the missing planes must all be foreign owned. I did some reading and learned that the hex IDs reported in ADS-B are from the International Civil Aviation Organization (ICAO), and that each country is assigned its own block of values in the address space. For example the US fits in A00000 to AFFFFF (which explains why I always see A's in my data), while Portugal is in 490000 to 497FFF. Annoyingly, I couldn't find an official table with all the country codes in it anywhere. I did find a website that had deduced the info and put it into a table. I grabbed it and did a lot of awking to put it into a lookup table my scripts could use. Here's where the 15 remaining planes were from, sorted by country:
C00738 22:29:12.396 22:50:48.658 Canada
C00964 22:30:02.529 22:40:50.856 Canada
C04852 22:57:57.379 23:16:09.175 Canada
C06E87 22:29:06.825 22:38:57.286 Canada
C08048 22:31:58.590 22:43:20.798 Canada
780A5B 23:16:51.247 23:21:39.138 China
780A70 22:29:07.154 22:29:44.770 China
780DA9 22:44:36.948 22:52:14.966 China
0D049E 23:22:46.770 23:25:08.781 Mexico
0D083B 22:55:46.443 23:02:04.836 Mexico
0C206B 22:44:08.180 22:50:31.290 Panama
52027A 23:10:56.513 23:19:52.647 (reserved, EUR/NAT)
899103 22:34:37.444 22:42:35.777 Taiwan
072233 22:29:13.247 22:32:35.813 unknown
A22E75 22:42:30.730 22:55:33.598 United States
The last plane there is a US plane, which should have been in the FAA database. FlightAware gave me the tail fin (N24JG), which the FAA told me had a December renewal rate. My guess is that the plane was just in-between renewals. In any case it was an interesting plane because it's owned by Jeff Gordon, Inc. Jeff Gordon is a race car driver, so I guess I did spot a celebrity. Neat.
Military/Surveillance Flights
The next unknown was 072233. I didn't find this registered anywhere, but Google searches turned the number up in lists where people monitor military plane activity. They reported this as 09-72233, which they say is a US Army UH-72A or EC45 helicopter (unarmed).
The final plane was 52027A, which caught my eye because it falls into a NATO band of the ICAO numbers (I believe). I looked it up in the raw dump1090 data and found that it also used the callsign IRONS12, which sounds like a tough-guy military callsign. I was hoping it might be the F15 that intercepted four planes during the superbowl (and escorted them to Livermore), but I think it's actually a surveillance plane. I found references to an IRONS12 callsign being used by an RC-26B with serial 920372 in the Bay Area the week before the superbowl (and leaving after). The RC-26B appears to be an Air National Guard plane with sensors for filming and tracking, and serves to "bridge the gap between Department of Defense and civil authorities". Now that I think about it, a surveillance plane is a lot more interesting than the F15s that the news covered.
Flight Times
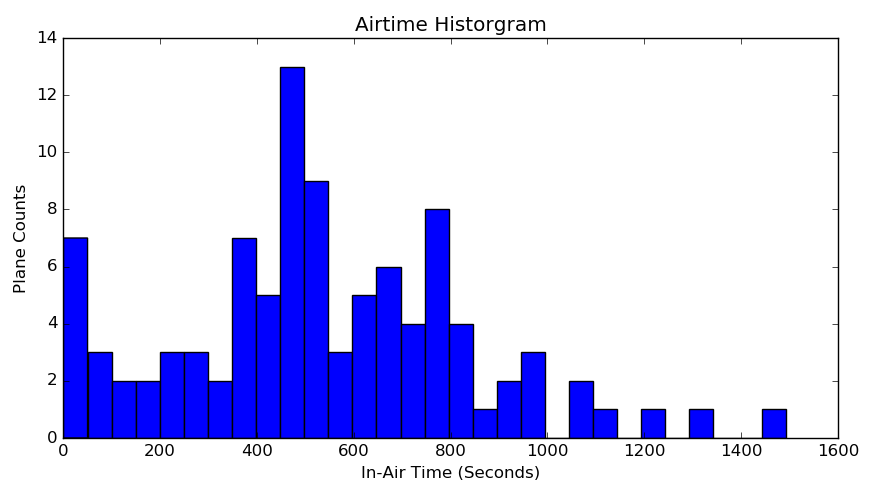
The only other analysis I did on this data was look at how long planes were in the air (or otherwise chirping their ADS-B info). Given my antenna configuration that night, most planes were only visible for about 10-15 minutes. The emergency helicopter though operated for more than 20 minutes. I'd been hoping to see some private planes with long running times (a sign that they were sitting at the airport waiting for their owners to show up), but that didn't happen.
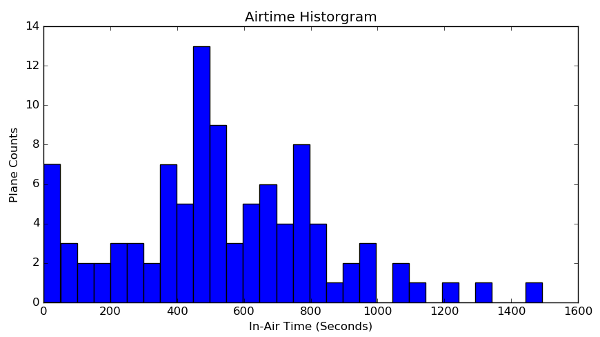
Code
I've put the data and the scripts used to do these plots on github. The country code lookup table I made for this work is also in the repo.
github:flight-classifier