2023-05-19 Fri
pub smartnics hpc
Our ASCR SmartNIC project published the following unclassified unlimited release (UUR) paper.
Abstract
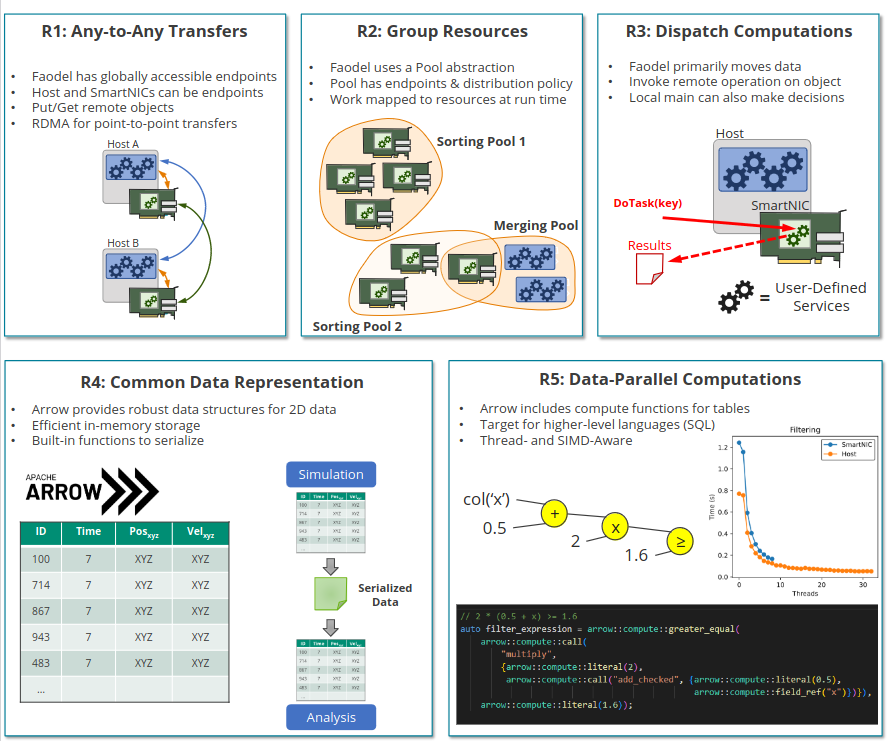
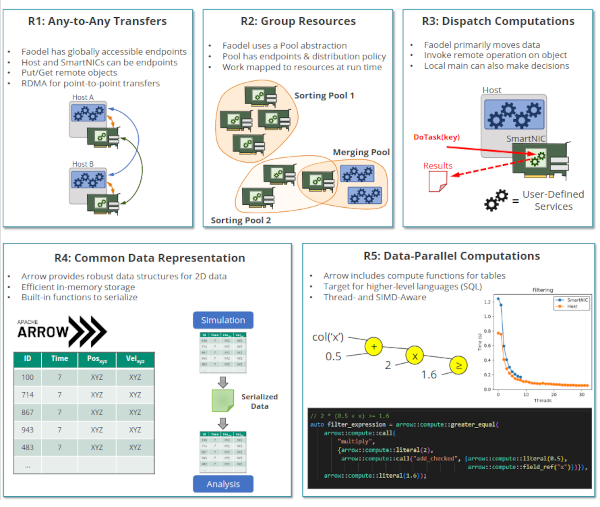
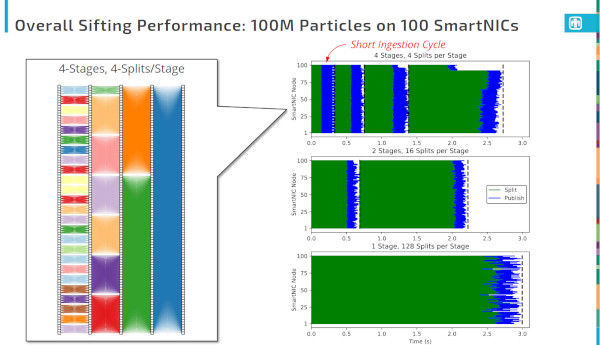
Advanced scientific-computing workflows rely on composable data services to migrate data between simulation and analysis jobs that run in parallel on high-performance computing (HPC) platforms. Unfortunately, these services consume compute-node memory and processing resources that could otherwise be used to complete the workflow's tasks. The emergence of programmable network interface cards, or SmartNICs, presents an opportunity to host data services in an isolated space within a compute node that does not impact host resources. In this paper we explore extending data services into SmartNICs and describe a software stack for services that uses Faodel and Apache Arrow. To illustrate how this stack operates, we present a case study that implements a distributed, particle-sifting service for reorganizing simulation results. Performance experiments from a 100-node cluster equipped with 100Gb/s BlueField-2 SmartNICs indicate that current SmartNICs can perform useful data management tasks, albeit at a lower throughput than hosts.
Publication
- Compsys Paper Craig Ulmer, Jianshen Liu, Carlos Maltzahn, and Matthew L. Curry, "Extending Composable Data Services into SmartNICs" in Second Workshop on Composable Systems (CompSYS), May 2023.
Presentation
2022-10-03 Mon
pub io hpc
We published the following unclassified unlimited release (UUR) technical report advocating for S3 storage use.
Abstract
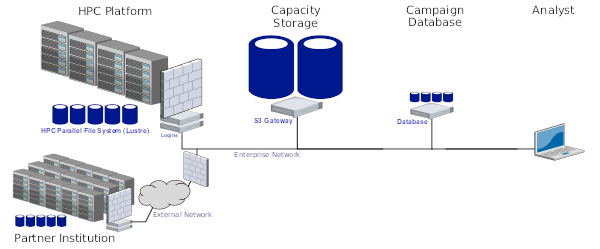
Recent efforts at Sandia such as DataSEA are creating search engines that enable analysts to query the institution's massive archive of simulation and experiment data. The benefit of this work is that analysts will be able to retrieve all historical information about a system component that the institution has amassed over the years and make better-informed decisions in current work. As DataSEA gains momentum, it faces multiple technical challenges relating to capacity storage. From a raw capacity perspective, data producers will rapidly overwhelm the system with massive amounts of data. From an accessibility perspective, analysts will expect to be able to retrieve any portion of the bulk data, from any system on the enterprise network. Sandia's Institutional Computing is mitigating storage problems at the enterprise level by procuring new capacity storage systems that can be accessed from anywhere on the enterprise network. These systems use the simple storage service, or S3, API for data transfers. While S3 uses objects instead of files, users can access it from their desktops or Sandia's high-performance computing (HPC) platforms. S3 is particularly well suited for bulk storage in DataSEA, as datasets can be decomposed into object that can be referenced and retrieved individually, as needed by an analyst.
In this report we describe our experiences working with S3 storage and provide information about how developers can leverage Sandia's current systems. We present performance results from two sets of experiments. First, we measure S3 throughput when exchanging data between four different HPC platforms and two different enterprise S3 storage systems on the Sandia Restricted Network (SRN). Second, we measure the performance of S3 when communicating with a custom-built Ceph storage system that was constructed from HPC components. Overall, while S3 storage is significantly slower than traditional HPC storage, it provides significant accessibility benefits that will be valuable for archiving and exploiting historical data. There are multiple opportunities that arise from this work, including enhancing DataSEA to leverage S3 for bulk storage and adding native S3 support to Sandia's IOSS library.
Publication
- SAND Report Todd Kordenbrock, Gary Templet, Craig Ulmer, and Patrick Widener, "Viability of S3 Object Storage for the ASC Program at Sandia". SAND2022-1538, October 2022.
2022-09-23 Fri
pub smartnics hpc
Our ASCR SmartNIC project published the following unclassified unlimited release (UUR) paper.
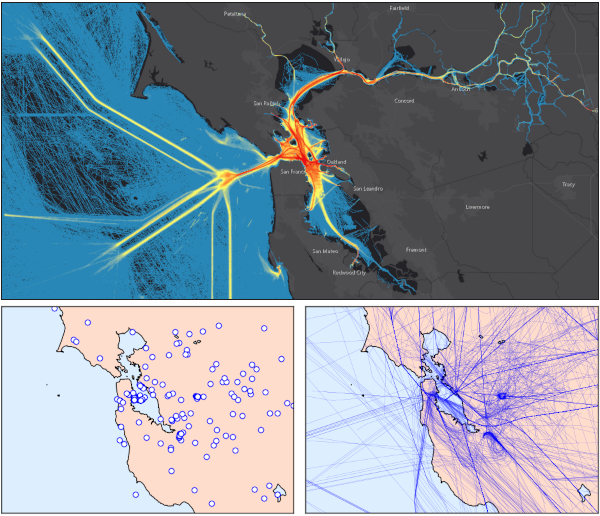
Abstract
Many distributed applications implement complex data flows and need a flexible mechanism for routing data between producers and consumers. Recent advances in programmable network interface cards, or SmartNICs, represent an opportunity to offload data-flow tasks into the network fabric, thereby freeing the hosts to perform other work. System architects in this space face multiple questions about the best way to leverage SmartNICs as processing elements in data flows. In this paper, we advocate the use of Apache Arrow as a foundation for implementing data- flow tasks on SmartNICs. We report on our experiences adapting a partitioning algorithm for particle data to Apache Arrow and measure the on-card processing performance for the BlueField-2 SmartNIC. Our experiments confirm that the BlueField-2's (de)compression hardware can have a significant impact on in- transit workflows where data must be unpacked, processed, and repacked.
Publication
I won an an individual Employee Recognition Award (ERA) for some work that I've been doing with Globus. At the award ceremony today I got to shake hands with the lab president and several VPs. Here's the ceremonial coin they gave me:

2022-04-15 Fri
pub data seismic
Our project published the following unclassified unlimited release (UUR) paper.
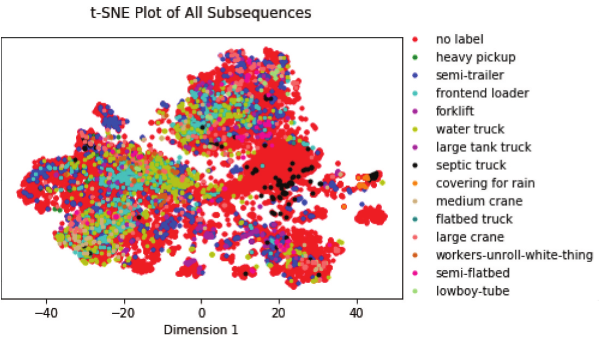
Abstract
Pattern-of-life analysis models the observable activities associated with a particular entity or location over time. Automatically finding and separating these activities from noise and other background activity presents a technical challenge for a variety of data types and sources. This paper investigates a framework for finding and separating a variety of vehicle activities recorded using seismic sensors situated around a construction site. Our approach breaks the seismic waveform into segments, preprocesses them, and extracts features from each. We then apply feature scaling and dimensionality reduction algorithms before clustering and visualizing the data. Results suggest that the approach effectively separates the use of certain vehicle types and reveals interesting distributions in the data. Our reliance on unsupervised machine learning algorithms suggests that the approach can generalize to other data sources and monitoring contexts. We conclude by discussing limitations and future work.
Publication